08 Mar 2020
什么是AOP
AOP(Aspect-oriented programming,面向切面编程) 的目的是为了解耦从而提高代码的模块化程度。开发的应用中可以根据功能分为“主业务逻辑”和“通用业务逻辑”,比如:某电商网站当下需要开发用户注册的功能并打印一些日志,注册用户就是主业务,打印日志是通用业务。除了日志还有事物管理、安全管理等等这些都可以划归到通用业务中,该通用业务有个专门的名词 cross-cutting concerns,在有的博客中将它翻译成 横切关注点 ,起初看到这个翻译的时候着实被懵到了,这到底是个什么鬼……….
想象一个场景:网站可不仅仅只在用户注册的时候打日志,商品查询、订单创建…….这些地方都需要的,而且通用业务也不只是打日志这一项,当每一个主业务中都夹杂着各种的通用业务时,开发和维护的难度也就增大了。
再回到打日志这个功能,每个主业务逻辑中负责打日志的代码的逻辑几乎是一样的,开发者将打日志得代码抽成方法被主业务调用就能让业务逻辑变的“干净清晰”,这个方式也可应用到其他的 cross-cutting concerns,而且这的确是个不错的办法,但“调用”没有将主业务和 cross-cutting concerns 彻底的分开,主业务逻辑还是包含了通用业务,尽管它只有一行代码而已。AOP 就做到了彻底分开(解耦),主业务逻辑、通用业务逻辑封装到两个不同的方法中,AOP 通过在主业务方法上做“标记”的方式告诉 Spring Boot:用户注册的时候记得打日志,具体的格式在通用业务方法中。
名词解释
AOP 涉及这里主要介绍 Aspect 、Advice 、Joinpoint、Pointcut 这4个(总共有8个),理解这四个就可以上手做东西了,其他的后续再研究吧。(先做完成主义,再修改优化,最后再做完美主义)。
-
Aspect (切面):这是个类,它包含了某个 cross-cutting concerns 的各种场景下的业务逻辑,比如:用户注册的业务需要日志格式“用户名+日期”,创建订单的业务需要的日志格式是“用户+商品名+价钱+日期”。为满足场景需求,我们可以创建切面 LoggerAspect.class ,里面包含两个方法,method1 负责产生用户注册的日志,method2 负责创建订单的日志。
-
Advice (建议):这是个方法,里面包含着 cross-cutting concerns 在某个场景需求下要执行业务逻辑,上面的 method1 和 method2 都是 advice。
-
Joinpoint (连接点):通过上面两个解释我们可以意识到,当主业务方法执行的时候也执行了 Aspect 中的某个 Advice,joinpoint 规定了当主业务方法(假设方法名是:registerUser )执行到什么时刻时 允许 advice 执行。允许的时刻如下:
- registerUser 执行之前;
- registerUser 执行之后,不论 registerUser 执行成功还是失败;
- registerUser 执行之后,而且要执行成功;
- registerUser 执行出现异常的时候;
-
Pointcut (切点):joinPoint 给出了允许 advice 执行的时刻的候选集,切点指的是 advice 从候选集中挑个时间让自己被执行。Before、After、AfterReturning、AfterThrowing、Around,根据单词的字面意思和上面的允许时刻对比下,就差不错明白了。
使用方法
目前有基于 spring AOP 和 AspectJ 两种 AOP 框架,在一些资料上看到两个框架兼容且 AspectJ 的速度是spring AOP 的8到35倍,所以本文基于后者(配置方法)。同时将基于 AspectJ 的 AOP 应用到开发中也有两种方式:路径切入 和 注解切入 。
通过路径切入
@Aspect
@Component
public class LoggerAspect {
@Pointcut("execution(public * com.forum.controller.*.*(..))")
public void log() {
}
@Before("log()")
public void doBefore(JoinPoint joinPoint) {
........
}
@After("log()")
public void doAfter() {
........
}
}
1、新建切面类 LoggerAspect 上面加俩注解 @Aspect、 @Component 缺一不可。
2、@Pointcut 指定要”切“谁,可以精确到包、类或者方法上。
3、@Before 指定切点以及要执行的业务逻辑。
4、@After 指定切点以及要执行的业务逻辑。
这种方式的优点是:当 @PointCut 定位到包或者类时,可以执行批量切入。
通过注解切入
自定义注解,不做任何操作,全当是个”标识符“。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Loggable {
}
定义切面,execution(* *(..)) 表示这个advice只在执行的时候调用,否则会执行两次。
@Aspect
@Component
public class LoggerAspect {
@Before("@annotation(com.demo.aop.aspcet.Loggable) && execution(* *(..))")
public void doBefore(JoinPoint joinPoint) {
........
}
}
在主业务代码中使用,该业务代码的功能是创建employee。
@Service
public class EmployeeService {
@Loggable
public Employee createEmployee(String empId, String name) {
return new Employee(empId, name);
}
}
@Loggable 注解将切入点精确到了方法上。所以这种方式的优点是灵活、也比较干净。
对“横切关注点”的理解
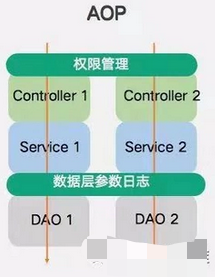
上面提到“横切关注点”这个翻译一直让我很困惑,当看到这张图时我有点理解了,这个翻译还是有点道理的,只不过是有点形象罢了。
如上图所示,程序是从一般是从Controller层到Service,再到DAO层最后又从Controller层返回执行结果,整个流程如箭头所示从上到下是纵向处理的。但每个Controller执行时都需要验证参数、认证权限、打日志等等,这些通用功都是在切面中完成的,每个Controller的认证权限代码是一样的,每个Controller打日志的代码是相似的…….。请求在切面中执行相同或者相似的代码,在各自的Controller中执行对应方法的业务逻辑,这就相当于某个通用功能将正常的请求执行给“横切”了一样。
29 Feb 2020
原文在此
char 和 varchar 类型很相似,但在存储和读取方式、支持的最大长度、是否保留尾随空格这些方面有很大不同。
char 和 varchar类型在创建时声明打算存储的最大字符个数,例如:char(30)表示最大可存储30个字符。
char类型列的长度在建表时就已经通过声明固定下来了,并且该长度在0-255之间。当char类型的值在存储时,字符串末尾如果有空格也依旧会存储起来,比如:char值为’diego ‘。当SQL开启 PAD_CHAR_TO_FULL_LENGTH模式时,字符串的尾随空格会被读取,否则尾随空格会被去掉。
varchar类型列存储可变长度的字符串,且字符串的长度在0-65535之间。varchar的有效最大长度取决于行的最大尺寸(每行最大尺寸65535bytes,这些字节被所有的列共享)和使用的字符集种类(latin1、utf8等等)。
与char不同,varchar需要1byte或者2byte的空间存储字段所占的字节数。当字段所占的字节数小于255时,需要1byte空间存储字节数,当字段所占的字节数大于255是,需要2byte空间存储。
如果 strict SQL mode 没有开启,当分配给char或者varchar列的值超过了最大长度限制,这个值会被mysql自动截断来适应列的长度并且发出 warning 。对于非空格字符串截断,可以通过开启严格sql模式,使mysql报异常(而不是警告)并且静止该值的插入。推荐开启该模式。
对于varchar列,无论使用哪种SQL模式,插入前都会截断超出列长度的尾随空格,并生成警告。 对于char列,无论SQL模式如何,都将以静默方式执行从插入值中截断多余尾随空格的操作。
下面这张表通过存储不同的字符串到char(4)列和varchar(4)列的结果展示这两种类型的不同。假设列采用单字节字符集:latin1。(latin1: 一个字符占一个字节,utf8:一个字符占三个字节)
| value |
char(4) |
Storage required |
varchar(4) |
Storage required |
| ’ ‘ |
’ ‘ |
4 bytes |
’ ‘ |
1 byte |
| ‘ab’ |
‘ab ‘ |
4 bytes |
‘ab’ |
2 byte |
| ‘abcd’ |
‘abcd’ |
4 bytes |
‘abcd’ |
5 byte |
| ‘abcdefgh’ |
‘abcd’ |
4 bytes |
‘abcd’ |
5 byte |
23 Feb 2020
Flyway是个开源的数据库迁移工具(把migration翻译成迁移感觉听不顺嘴的,暂且这么叫吧)。它提供了 SQL和 JAVA两种方式做migration,并且使用也很简单。基于Spring Boot的应用开发场景,本文内容:
一. 添加依赖和配置
build.gradle:
dependencies{
implementation('org.flywaydb:flyway-core')
}
application.properties:
spring.datasource.url=jdbc:mysql://localhost/demo_database_1
spring.datasource.username=root
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
debug=true
flyway.baseline-on-migrate=true #used if database has some already table
flyway.enabled=true
flyway.url=jdbc:mysql://localhost/demo_database_1
flyway.user=root
flyway.password=
二. 使用方法
sql方式的migration需要创建一个 .sql 文件,sql方式一般用来创建表、删除表,字段的添加、删除或者修改字段的名字、类型和初值等。如要想要对标中已有的数据执行逻辑操作,那就需要采用java的方式做migration,同样也需要创建 .java 文件。在spring boot程序启动的时候,flyway会按照顺序执行migration文件。
2.1migration文件的命名和放置的地方
其中:
- V 是migration版本的前缀;
- 1 是版本号,从1往上增加,不能重复;
- Add_new_table 是文件名;
.sql文件放在 src/main/resources/db/migration 路径下;
.java文件放在 src/main/java/db/migration路径下;
2.2 SQL方式的migration
直接写SQL语句就可以了,很简单的。场景:创建一个employee表。
创建文件:resources/db/migration/V1__Create_Employee_Table.sql
SQL语句:
CREATE TABLE `employee` (
`employeeId` int(11) NOT NULL AUTO_INCREMENT,
`employeeName` varchar(255) DEFAULT NULL,
`employeeRole` varchar(255) DEFAULT NULL,
PRIMARY KEY (`employeeId`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT;
2.3 JAVA方式的migration
创建的java文件中必须实现 SpringJdbcMigration 接口,在重写的 migration方法中编写业务逻辑。
场景1:查询employee中的员工数目。
package db.migration;
import org.flywaydb.core.api.migration.spring.SpringJdbcMigration;
import org.springframework.jdbc.core.JdbcTemplate;
public class V4__Another_user implements SpringJdbcMigration{
@Override
public void migrate(JdbcTemplate jdbcTemplate) throws Exception {
int result = jdbcTemplate.queryForObject(
"SELECT COUNT(*) FROM EMPLOYEE", Integer.class);
}
}
场景2:查询所有员工的名字。(查询单个字段)
List<String> name = jdbcTemplate.queryForList(
"select distinct(employeeId) from employee", String.class);
场景3:查询所有员工的ID、name和role。(查询多个字段)
用 RowMapper接口将查询结果映射到java对象。
public class EmployeeRowMapper implements RowMapper<Employee> {
@Override
public Employee mapRow(ResultSet rs, int rowNum) throws SQLException {
Employee employee = new Employee();
employee.setId(rs.getInt("id"));
employee.setName(rs.getString("name"));
employee.setAddress(rs.getString("role"));
return employee;
}
}
@Data
class Employee{
int id;
String name;
String role;
}
对应的migration方法中的查询语句如下:
String query = "SELECT employeeId as id, employeeName as name, employeeRole as role FROM EMPLOYEE";
List<Employee> employees = jdbcTemplate.queryForObject(
query, new EmployeeRowMapper());
场景4:查询姓名是“diego”的员工的信息。(带参查询)
String query = "SELECT * FROM EMPLOYEE WHERE employeeName = ?";
Employee employee = jdbcTemplate.queryForObject(
query, new Object[] { “diego” }, new EmployeeRowMapper());
场景5:将所有员工的ID在原有基础上加1,这个逻辑操作很简单,但在实际应用中会出现很复杂的逻辑操作。(批量更新)
//获取所有员工信息。
String query = "SELECT employeeId as id, employeeName as name, employeeRole as role FROM EMPLOYEE";
List<Employee> employees = jdbcTemplate.queryForObject(
query, new EmployeeRowMapper());
//更新
String updateUserInfoSQL = "update EMPLOYEE set employeeId = ? where employeeName = ?";
jdbcTemplate.batchUpdate(updateUserInfoSQL, new BatchPreparedStatementSetter() {
@SneakyThrows
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Employee employee = employees.get(i);
ps.setString(1, employee.getId()+1);
ps.setString(2, employee.getName());
}
@Override
public int getBatchSize() {
return employees.size();
}
});
21 Feb 2020
学习还是需要做笔记的,如果读书是输入那么笔记就是对应的输出了。脑子里觉得”理解了“的内容当把它用文字以书面形式表达出来的时候是对刚才的理解进一步地整理、确认(可能这种理解存在在着错误)。写博客也是做笔记的一种形式,但它却更费时间,之前的博客废话有点多了,以后注意,毕竟效率也是很重要的。进入正题…………
mysql的逻辑架构(如下图所示):
- 连接器管理连接、校验权限、维持和管理权限,当我们在terminal中输入
mysql -uroot -p12345时就通过连接器建立客户端与mysql服务器的连接。本地使用的时客户端和服务器都在同台电脑上,上述命令可以直接建立连接。
- 查询缓存按照
key-value的格式存放之前的查找记录。key是分析器放入的,对应的value是执行器放入的。当执行SQL语句的时候会先查询缓存有无命中,如果有则直接返回查询结果。当一张表有update操作时,这张表上的查询缓存全部失效。
- 分析器会对要执行的SQL语句进行词法分析和语法分析,判断语法是否正确,要查询的结果、查询的条件等信息。
- 优化器会在多个执行方案找出最优方案。比如:通过优化器模MySQL已经知道当前语句要查找某个记录,优化器会决定是走全表查找还是按索引查找。
- 执行器根据优化方案执行具体的查找操作。先校验当前用户对表有没有查找权限,如果有则执行器通过引擎提供的接口打开表,按照全行扫描或者索引查找记录,最后将满足条件的记录组成结果集返回给客户端。
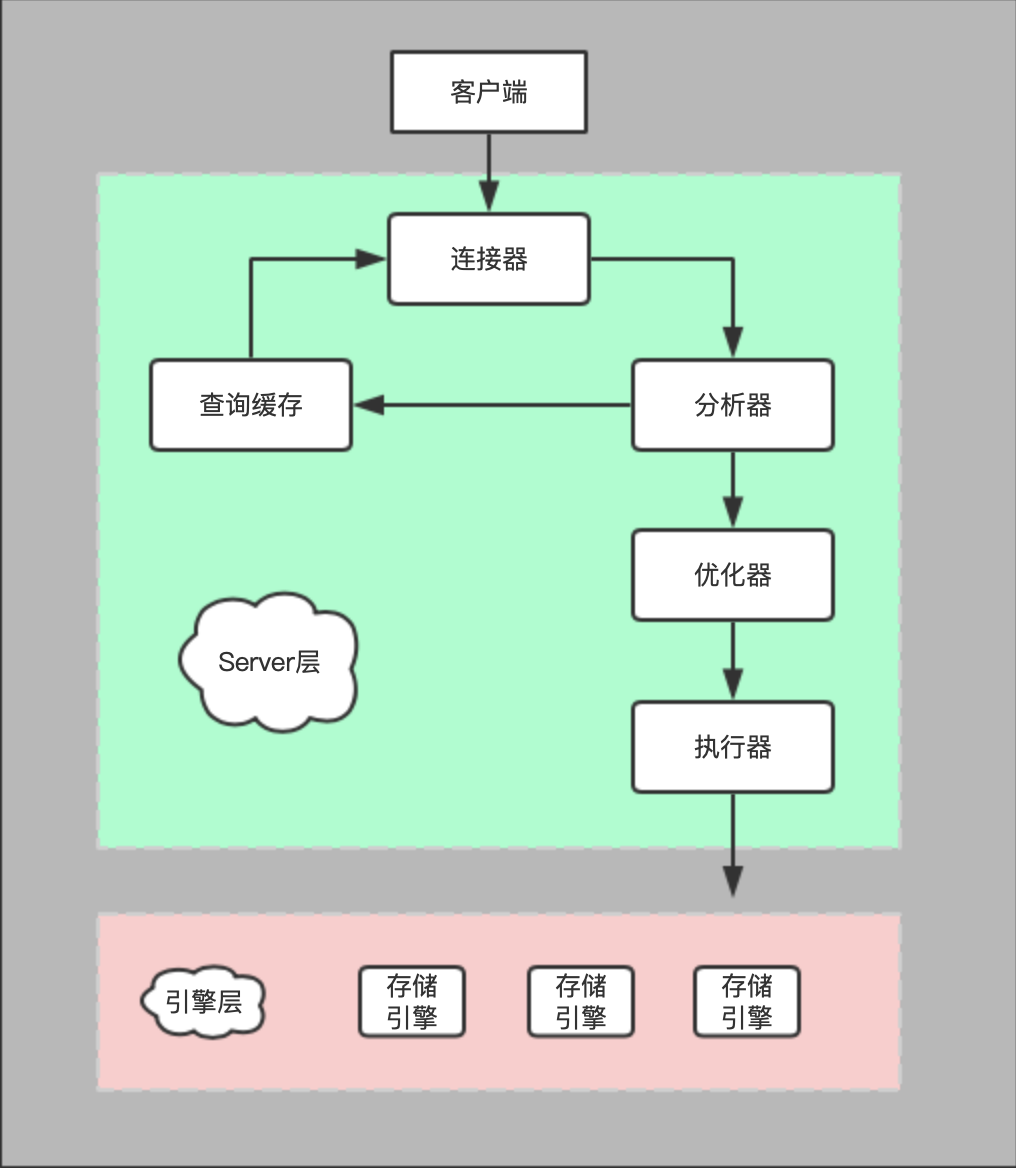
mysql的逻辑架构图
一条SQL语句的执行过程。
创建表:
create table T(ID int primary key, c int);
更新一行记录:
update T set c=c+1 where ID=2;
update语句执行流程如下:
- 执行器要调用引擎接口拿到ID=2这行记录。(服务层)
- 引擎层直接在ID索引树上查找目标数据,如果目标数据所在的数据页在内容中,则直接返回给执行器,否则,先要从磁盘中读数据页到内存中,再将目标数据返回给执行器。(引擎层)
- 执行器拿到行数据后,给对应字段的原值+1得到一行新的数据,再调用引擎接口将新数据交给引擎层去写。(服务层)
- 事务执行commit语句后,引擎层将拿到的新数据更新到内存中,同事将这个更新写到
redo log里面,此时redo log处于prepare状态。然后告诉执行器新数据写完了,可以提交事务了。(引擎层)
- 执行器收到引擎层的“可提交”通知后将刚才的更新操作写到到
binlog里面。(服务层)
- redo log写入磁盘。(引擎层)
- binlog写入磁盘。(服务层)
- 执行器调用引擎提交事务接口,引擎把刚刚写入redo log的状态标改成提交(commit)状态,更新结束,(WAL机制)。(引擎层)。
第4步后将redo log的提交分为了prepare和commit两个阶段,这就是两阶段提交
更新的执行过程中在服务层和引擎层来回切换赶脚好乱,我第一次看感觉就是头大,但梳理下还是很清楚的,搞清楚几个问题就可以初步理解了:
1 mysql服务端由那几部分构成?
大体来说,MySQL可以分为服务层和引擎层两部分。
服务层包括连接器、查询缓存、分析器、优化器、执行器等大多数服务功能,数据的计算也在这层执行。引擎层**只负责数据的读取和存储。
服务层只有一种,但引擎层支持多重存储引擎,比如:MYISAM、InnoDB、Memory都是具体的存储引擎,服务层也都支持。InnoDB是最长用的存储引擎。
2 redo log和binlog是什么?
简单说,这两个都是日志,
redo log是InnoDB引擎特有的日志,binlog是服务层的日志(所有引擎都能使用该日志)。
redo log是物理日志,记录了每个数据页上做了什么修改,比如将第 0 号表空间的 100 号页面的偏移量为 1000 处的值更新为 2,binlog是逻辑日志,有两种模式:statement格式下记录时sql语句,rows格式会为更新的行记录两条内容,一条是更新前的内容,另一条是更新后的。(所有的引擎都能看懂)。
redo log是循环写的,总共大小默认4G,当日志写满是会把最开始的记录刷到磁盘中,腾出空间给新记录。binlog是追加写的,类似于文件一张一张写满又新建一张继续追加写,永远不会覆盖。
4 为什么要记录两份日志?
mysql需要做两样工作:备份和crash-safe(突然崩溃后不能丢失数据)。
当只有redo log:因为它是循环写的,写到末尾是要擦除开头重新写,这样就没法保存历史日志,所以能用来备份。
当只有binlog不能保证MySQL有crash save能力。(至于原因,看了好些资料觉得都没有完全解释,或许是我吗没有理解)
5 MySq如何保证crash save?
Crash save是指mysql服务器宕机重启后,能够保证:所有已提交的事务的数据仍旧存在,所有未提交的事务的数据回滚。MySQL的两阶段提交恰好保证了mysql具有crash save能力,来看下具体的细节:
当写redo log成功,在binlog之前宕机,MySQL重启时发现有redo log中的事物却没在binlog中找到对应的完整事务,则回滚。
当写redo log成功,写binlog成功,但在redo log状态变为commit时宕机,MySQL重启时发现redo log中完整的事物能在redo log中找到对应的而且也完整,则重新将这个事务提交。
6 MySQL怎么知道binlog中的事物是否完整,怎么将redo log和binlog中的事务对应起来?
binlog中的事务都是有完整格式的:
statement格式:事务后面会有个commit。
row格式:最后会有个XID event。
事务都有个共同的字段XID,redo log和binlog通过这个字段将相同的事务关联起来。
7 什么是WAL(write-ahead log)机制, 好处是什么?
WAL机制是当执行更新语句时,引擎将更新语句记录在redo log上提后向客户端返回“更新成功”,等到MySQL觉得合适的时间在将redo log上的刷到磁盘上。
这样做的好处是:直接把数据写到磁盘上,频繁的随机写会耗费大量的时间。写在redo log上就可以把随机写变成顺序写,效率提高好多。
29 Dec 2019
tensorflow serving是tf官方推出的专为生产环节设计的机器学习模型服务系统(TensorFlow Serving is a flexible, high-performance serving system for machine learning models,designed for production environments),使用它可以很方便的将训练好的模型部署成web服务,并通过HTTP或GRPC的方式访问。
根据官方资料模仿出demo很容易,但往深走或者做些修改解决场景需求还是着实花了一些功夫的,我承认这跟我不熟悉tensorflow有些关系,但更多的时间花在了理解概念和做实验上了。顺便再吐槽下,官方的introduction和tutorial有点少呀。
tensroflow serving中很重要的概念是SavedModel,跟checkpoint中以.ckpt或.h5的格式存放训练好的模型一样,也是模型的一种存放格式(下图),saved_model是模型的存放路径,1表示模型的版本(version)每个版本都是一个单独的子目录,如若有其他版本,那么版本号一次递增。saved_model.pb是训练好的模型的图,variables是训练好的权重。 tensorflow serving识别这种格式并且通过load它就能把已训练好的模型部署起来。
saved_model
└── 1
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
接下来的主要工作就是怎么生成这个SavedModel,官方资料中把这个过程叫做export model。官方资料的代码开起来太费劲了,我在此只想把这个过程讲清楚所以就弄了个简单点的代码(如下)。输出路径和输入输出维度、类型这个就不再啰嗦了。tensorflow采用SavedModelBuilder模块导出模型(当然还有别的export方法),它将与训练的模型的snapshort保存到硬盘上以便之后在的inference时直接load。先构建builder对象;再用builder.add_meta_graph_and_variables(...)方法将与训练模型的图和参数值添加到builder中;最后调用builder.save()将pretrain model保存成saved model。
# 输出路径
export_path_base = "./savedModel"
export_path = os.path.join(tf.compat.as_bytes(export_path_base),
tf.compat.as_bytes(str(1)))
print('Exporting trained model to', export_path)
# 输入输出变量的维度和类型
x = tf.placeholder('float', shape=[None, 3])
y_ = tf.placeholder('float', shape=[None, 1])
# 构建SavedModel
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
tensor_info_x = tf.saved_model.utils.build_tensor_info(x)
tensor_info_y = tf.saved_model.utils.build_tensor_info(y_)
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'input': tensor_info_x},
outputs={'output': tensor_info_y},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))
legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'prediction':
prediction_signature,
},
legacy_init_op=legacy_init_op)
builder.save()
那剩下需要详细介绍的就是add_meta_graph_and_variables(...)方法了,貌似现在它变的很核心了(就使用而言它的确很核心),里面重要的是sess、tags、signature_def_map三个参数,源码在这里。
def add_meta_graph_and_variables(self,sess,tags,signature_def_map=None,
assets_list=None,clear_devices=False,init_op=None,train_op=None,
strip_default_attrs=False,saver=None):
-
sess里面包含有我们打算保存的训练的模型,这个在理解上不会有困惑的。
-
tags是我们给即将生成的SavedModel中保存的图(meta graph)打的标签,tf规定每SavedModel中的每个meta graph都必须指定标签,用于表示meta graph的作用和使用场景,比如meta graph是用来做train还是serve,它需要用到CPU还是GPU。而且在load SavedModel时只有tags匹配,loader API才能加载成功,否则报错。tf提供了四种常见的标签。因为我们创建的SavedModel是用做serve的,所以上面代码中的tf.saved_model.tag_constants.SERVING作为标签。
-
signature_def_map的作用是指定了导出模型的类型和指定当启动infenrece过程时输入和输出的tensor,不可谓不重要。对这块的数据组织格式刚开始有点误解,后来有点想明白了,介绍性的文字说明不能吝啬的。接下来从头捋一下,看看signature_def_map是怎么来的。
x、y_是我们定义输入、输出tensor,先要把tensor转换成TensorInfo proto结构的数据,为什么要转换,是因为tf人家的产品这么设计的(这个解释当然不具有说服性,但作为使用产品的用户,不管设计师的考量如何,还是理解和接受吧,主要精力还是应该放在基于它的应用开发上,出于兴趣自己可以研究研究),当然tf也同时提供了转换工具可供用户调用,所以不必纠结于为什么要转换,调两行代码轻松搞定继续后面的开发吧。
tensor_info_x = tf.saved_model.utils.build_tensor_info(x)
tensor_info_y = tf.saved_model.utils.build_tensor_info(y_)
signature_def_utils.build_signature_def(...)方法是SavedModel提供构建signature的API之一。这个方法有下面三个参数:
inputs={'images': tensor_info_x}指定了输入的tensor info。outputs={'scores': tensor_info_y}指定了输出的tensor info。method_name指定了inference过程调用的方法,如果是预测请求,则method_name的值应该指定为tensorflow/serving/predict,当前不要费时间问为什么,产品就是这么设计的,更详细的信息在这里。
下面在代码中我们prediction_signature中构建了一个signature,注意看下,prediction_signature是tuple类型的,当时很困惑为什么不是单独的signature呢?后来有点明白了,对于同一个inference过程,tf serving支持多种格式的数据输入,比如:inference是用来做猫狗分类的,图片也许是以tensor格式输入的,也有可能是以base64格式输入的,在里面再转换成tensor,只需要调用不同的method_name就可以了。
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'input': tensor_info_x},
outputs={'output': tensor_info_y},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))
接下来只需要给prediction_signature配上key(这个key叫做signature_def)构建个map怼到对应的参数上去就行了。
builder.add_meta_graph_and_variables(...,
signature_def_map={'prediction':prediction_signature,},
legacy_init_op=legacy_init_op)
最后用命令行工具saved_model_cli可以查看下我们保存好的SavedModel:
saved_model_cli show --dir ./savedModel/1/ --tag_set serve --signature_def prediction
结果如下:
The given SavedModel SignatureDef contains the following input(s):
inputs['input'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
name: Placeholder:0
The given SavedModel SignatureDef contains the following output(s):
outputs['output'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1)
name: add:0
Method name is: tensorflow/serving/predict
整个SavedModel的制作过程到现在算是介绍完了,不过还需要再加点东西这块才算比较全面些:
- 当SavedModel的serve启动后,该怎么根据signature组织相应的HTTP POST RequestBody数据呢。
- 怎么把已有的SavedModel 载入后稍加修改再保存成一个新SavedModel。
- 怎么把已有的checkpoint(.pb、.ckpt、.h5)转化成SavedModel。
- SavedModel支持自定义结构数据输入,比如:图片以base64格式输入。