24 Dec 2019
记得刚开始上手tensorflow的时候被各种写法搞的晕头转向的,看到checkpoint总是莫名的会紧张些,它就像开发中的持久化一样,把刚才在内存中跑的结果给保存到磁盘上用于日后的使用。但他又比mysql更黑盒些,只能看到文件名以及文件的解释,对于里面到底是什么呢,一点也都不知道。至于存储的对错与否,不要意思,即使是restore了也不能精确的确认,除非出现大bug导致程序跑不通,那会才知道“哦哦,保存有错误”而已。不过现在看来这些担心和心里的紧张,大都只会出现在那些本身就不自信的小白身上,因为他们知道的却清楚,才月会对自己写的代码有信心。
这篇文章的内容大多是翻译过来的,原文在这里。这个blog不知道是什么时候写的,但是看它最早的评论的时间是在三年前
这篇文章主要解释了四个问题:
- tensorflow模型的文件结构是怎么样的。
- tensorflow模型该怎么保存。
- 预测或者迁移学习的时候该怎么restore模型。
- 怎么使用导入的预训练模型进行再次训练(fine-turning)或者修改。
1. TF模型的文件结构
当我们训练完毕一个神经网络后,我们要把训练好的网络保存起来日后使用或者部署到生产环节。那么,什么是tensorflow(tf)模型(model)?tf model主要包括网络的设计(图,graph)和我们训练好的网络参数。因此,tf model有两个主要的文件:(1)元图(meta graph)它是个保存tf graph的协议缓存(protocol buffer)比如像变量、操作、集合,以及他们之间的前后关系,这个文件的后缀名是.meta。(2)检查点文件(checkpoint file)这是个二进制文件里面包含着网络中所有变量的值,这些值是用来对号入座填到元图的变量中的,文件扩展名是.ckpt。不过随着tensorflow版本的升级这个文件发生了改动,0.11版以后的ckpt文件有两个文件构成:
# 0.11版以前的模型结构
inception_v1.meta
inception_v1.ckpt
checkpoint
# 0.11版以后的模型结构
inception_v1.meta
inception_v1.index
inception_v1.data-00000-of-00001
checkpoint
checkpoint文件中只是做为一个记录,保存了着最新的checkpoint文件的名称。
2. TF模型的保存
在tensorflow中要想保存图和参数,就必须先创建出tf.train.Saver()的对象。而且只有当变量在session中时,它才值有值的,要不然只是一个”壳“而已。
未写完………
18 Dec 2019
工欲善其事,必先利其器,开发工具这个东西觉得折腾下还是有好处的。但常常感觉专门抽出时间搞这个浪费时间,更常见的现象是已经明显感觉到当前的开发工具用的很别扭,而且告诉自己等这个忙完了要搭一个更方便的工具,到最后却没下文了直到下次再次遇到这种感觉。我这会就是再次遇到了,想用VSCode连接服务器上的jupyter notebook运行tensorflow代码,这样在本地的VScode中直接写代码就方便了很多。整个过程很简单,我自诩记性也不错,但还是不如这白纸黑字来的保险,查资料也是很花时间的。
首先是本机与服务器之间配置ssh就不仔细描述了,要是忘了google一下“ssh远程登录服务器”大把都是资料而且大多数说的都是对的。但最好在~/.ssh/config中按照下面的样子再配置下,ssh用起来会更方便的。
Host remote_server
HostName 119.254.92.61
User xuser
IdentityFile ~/.ssh/id_rsa
接下来是vscode这边要能远程连接到服务器上,记住不是在本地写代码然后再发送到服务器上,而是直接连接到了服务器的某个路径下,VScode对文件的增删改查就相当于是操作了服务器上这个路径下的对应文件(也许说的比较啰嗦,但是觉得概念还是要清楚的)。实现这个目的只需要3步:
- 在
扩展(EXTENSIONS)中搜插件Remote - SSH安装后再重新启动VScode。
- 鼠标点击VScode左下角的齿轮选择
命令模式(command paletten),mac对应的快捷键是shift+cmd+p。
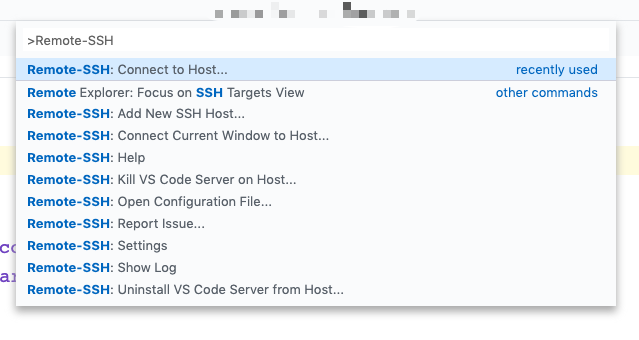
- 在VScode顶部中间弹出的下拉菜单中输入
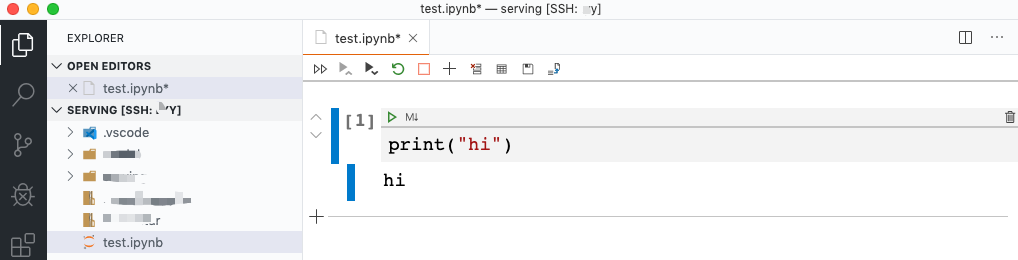
Remote - SSH点击图片中选中的选项,接下来再点击你要连接的服务器的名字就行了,最后会弹出一个新的VSCode。
vscode现在就可以远程连接服务器了,如果想写python代码,直接创建文件就可以了。
而服务器这边要能够创建jupyter noteboot,也就是些安装了,不难就是找起来有点麻烦。我喜欢用conda安装一个虚拟环境就是因为隔离了干净省心,真要是搞坏了直接删了重新建一个。服务器上的操作也只需要3步:
-
安装虚拟环境:
conda create --name notebook python=3.6
-
激活虚拟环境并安装jupyter notebook:
source activate notebook
conda install -c conda-forge jupyter notebook
-
创建一个notebook服务:
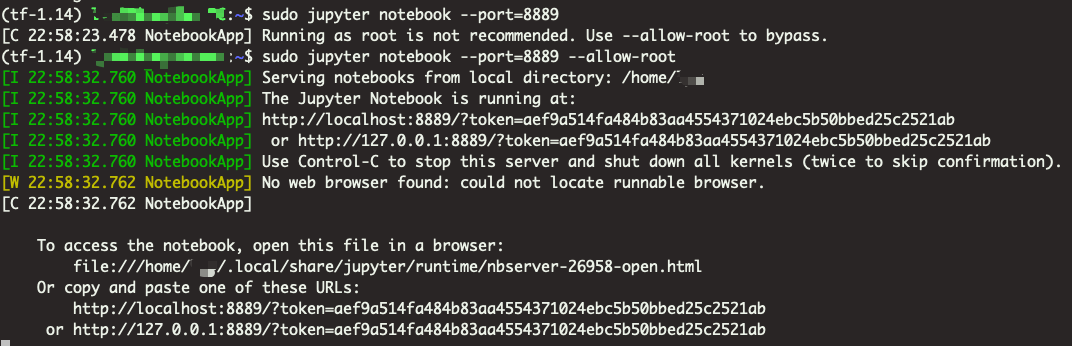
sudo jupyter notebook --port=8889 --allow-root
结果如下:最下面的两个URL就是刚才启动的服务的地址,我复制http://localhost:8889/?token=aef9a514fa484b83aa4554371024ebc5b50bbed25c2521ab,当然复制另一个也没问题。
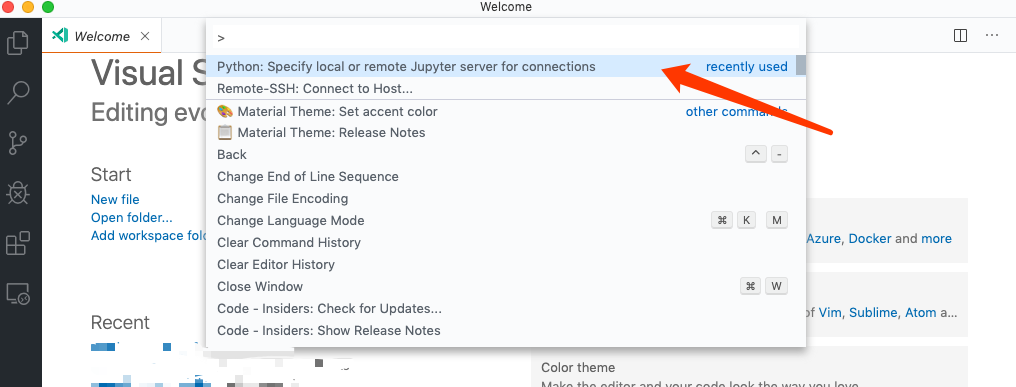
最后在已经连接到服务器的VScode中进入命令模式,点击下图下拉菜单中被选中的选项(好绕口,理解就好)。意思也很明显:指定一个本地或者远程的jupyter服务连接。
把刚才复制的URL粘贴进去,按回车。
创建一个jupyter文件测试下:
整个过程就这么简单而且内容也不多,但就是写了快两个小时吧,正好有今晚有时间就整理一下,以后就不需要google再去各种找了。后面几张大图看起来好丑,感觉以后要学一些有关排版设计的内容了,忽然想起自己曾今自学了一段时间PS,好久没用这会好像也忘差不多了。回头自己读刚才写的blog隐隐约约有种很着急的感觉,不知道是思维还是文笔的锅,总之有时间就多写写,“感觉”也是可以慢慢积累的呢~。
16 Dec 2019
序列化(Serialization)指的是将对象转化为字节流的过程,反序列化(Deserialization)顾名思义就是将字节流又重新转化成对象,并且保证转化前后对象的”状态“不变。序列化的目的就是为了将内存中的对象存在硬盘上或者进行网络传输。
序列化是个实例独立的过程,比如对象在一个平台上实例化后可以再其他平台上进行反序列化。但要求这些对象必须实现Serializable接口。对象实例化需要注意的地方主要两个,一是:对象的成员变量如果是基础类型,那是可以直接实例化的,如果是应用类型,那么这个成员变量也必须实现Serializable接口。二是:待序列化的对象强烈建议显式声明 final static serialVersionUID。关于这个 final static serialVersionUID一直很疑惑的,源码中给出的解释是这个UID是反序列化时做校验用的,当反序列化后的对象中的serialVersionUID与序列化对象中serialVersionUID不一样时报异常InvalidClassException。
设想一个这样的场景:我有一个对象序列化后存放在txt文本中,在文本中的其中一个属性的值给修改了但其他成员变量都保持不变,最后在反序列话回来,会不会报异常呢,如果不报异常那这个校验有什么用呢,如果报异常那很好奇啊,一个简单的long类型的UID(而不是一个类似于哈希码的东西)就能完成校验了,而且它校验的是什么呢。但仔细一想这个场景下反序列化应该是不会报异常的,要不然那得创建多少个类啊,而且校验应该不是校验属性值的。
再设想一个场景:有两个类Customer和Student,这两个类除了类名不一样外,所有成员变量都相同。先把Customer object序列化,再反序列化,不过把反序列化的结果类型转换成Student。显而易见这肯定是不成功的,实验结果是也报异常ClassCastException,不过这说明反序列化过程是成功的,只是Customer不能转成Student而已。
所以应该校验的场景是:对象序列化了以后,这个文本(暂且先这么叫吧)在“成员变量”(除值外)上发生了变化,也就是说文本被改动了。或者文本是以前序列化的,但是当下的Class变化了。对于前者来说更多的是文件内容损坏吧,因为存在文本中的东西人眼看起似懂非懂(就像下面一样)手动的精确修改应该很有难度,所以很少会人为修改,而且我尝试着删了一个可识别的字母,结果反序列化的时候报IOException。
’^@^Esr^@&com.yang.serialization.domain.Customer^@^@^@^@^@^@^@^A^B^@^CL^@^Gcompanyt^@^RLjava/lang/String;L^@^Bidq^@~^@^AL^@^Dnameq^@~^@^Axpt^@
那会猜后者的情况应该更常见些,但是当我给Customer类增加了一个属性age后,人家反序列化成功了,妥妥的,只是age值是null或者0(这个很好理解,本来就没有嘛)。我觉得自己要重新看看文档了,这本该很简单啊,但就是不按套路走啊,有些地方我肯定没有get到啊。最后我把Customer中的serialVersionUID的值给改了继续测试,报错信息如下:
java.io.InvalidClassException: com.yang.serialization.domain.Customer; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2
看到InvalidClassException我有点明白了,反序列化前后会校验serialVersionUID的值,如果不一样那绝对报异常,也就是反序列化失败了。如果一样,反序列化后的结果会”对号入座“,多了或者少了有自己的处理方式,总之不报异常。之前看的stackoverflow上写着:强烈建议自己显式声明serialVersionUID,serialVersionUID默认生成跟平台有关。现在明白了,默认serialVersionUID反序列化前后有时会不一样,这样本该是正确的反序列化结果报InvalidClassException异常,这应该就是真正的原因了。
这是个很简单东西,也许现在又钻了一次牛角尖,有时候想着用的时候记着声明下就可以了,再加上现在大多时候用java jacksion,所以可以不用深究的,不过还是过不了心里这一关。
04 Dec 2019
一直以来都想写一些东西,一是好记性不如烂笔头,把学过的东西整理出来加深映像,要是以后记忆模糊了可以翻过来看看;二是感觉写东西可以让我的心静下来,不会那么浮躁。这个link也是搞了好几次,学了忘了,忘了又学,正好今晚有时间把这个整理一下。
HATEOAS(Hypertext as the Engine of Application State)解读字面意思就是:超文本作为应用状态的引擎,实则是客户端与服务器以一种新的交互方式:链接,而且这种交互的优点是客户端无需提前知道与服务器的交互规则是什么。不知道理解的对不对,大概解释一下:RESTFUL API中共有四个level,其中level2是我们最常用的,它通过不同的HTTP方法对资源进行不同的操作,并且使用HTTP状态码来表示不同的结果。比如:HTTP POST用来创建资源,返回201表示创建成功;HTTP GET表示获取资源,返回200表示获取成功。这种交互方式客户端必须知道资源的URL以及操作方式,如果后端发生改动而有没有及时更新文档,那前端的操作肯定会报异常了。HATEOAS属于level3它的好处是资源的URl是后端动态生成且主动的暴露给前端的(这里:前端和客户端是同一个意思,后端和服务器是同一个意思),前后端是同步的,前端只需要通过”点击“的方式就能操作资源,就这么简单。还有一个优点是后端可以根据用户权限和资源状态动态的生成链接,这样连权限控制也直接给做了,总之就是HATEOAS好处多多。
Spring提供了org.springframework.hateoas依赖可以很快速的帮助开发者给资源创建URL,而其中主要使用到的是ResourceSupport、Link和ControllLinkBuilder这三个类。还有一个Resource类,它的源码描述是:General helper to easily create a wrapper for a collection of entities,其意思是轻松创建实体包装的通用助手,但是感觉它做出来的Link很丑,是真的很丑(第一次是听我老大说的,后来对比看了下,真是这样的,又丑又不好用)在最后面就会看到。
1、ResourceSupport
当每个资源需要为自己创建resource representation(我理解的是操作资源的各种链接,比如查找、删除、启动、停止等等)时都需要继承ResourceSupport基类,然后通过add()方法给自己添加需要的Link。
@ToString
@Getter
@AllArgsConstructor
public class Customer extends ResourceSupport {
private String customerName;
private String customerId;
private String companyName;
}
2、Link
Link中存储了资源的操作信息,比如我们创建一个静态的link表示一个customer的位置。
Link link = new Link("http://localhost:8080/spring-security-rest/api/customers/10A");
Link类有两个成员变量很重要的,也很最常用,rel表示链接和资源的身份关系,在外层,href表示实际链接本身,在内层,显然两个是嵌套关系。
通过执行customer.add(link);将资源和他所需要的链接组合起来,得到的结果如下。self的意思很明显,这个链接表示的是资源本身所在的位置。前端只需要”点击“一下链接,就能获取到这个资源,跟HTTP GET有相同的效果,但在操作上确变的简单了好多。
{
"customerId": "10A",
"customerName": "Jane",
"customerCompany": "ABC Company",
"_links":{
"self":{
"href":"http://localhost:8080/spring-security-rest/api/customers/10A"
}
}
}
3、ControllerLinkBuilder
上面的那条link是我们硬编码写的,如果不能实现动态生成Link那HATEOAS就失去了很大的优势了。ControllerLinkBuilder可以帮助我们动态生成Link。想一想对于那些没有resquestBody的HTTP操作,我们都是用特定的PathVariable拼出来从controller到method的URL对指定资源执行操作。而ControllerLinkBuilder的linkTo()方法就做了一件这样的事情,很简单,它拼出了需要的URL。生成方式也很简单:
linkTo(CustomerController.class).slash(customer.getCustomerId()).withSelfRel();
其中:
- linkTo()找要生成的URL的个根映射(也就是基路径)在哪,一般都在Controller.class上。
- slash()在基路径后面追加子路径,这个方法是可以连续追加好几次的,直到拼出最后需要的URL为止。
- withSelfRel()他给URL添加了
self和href两个属性。具体的意思和最后显示的格式在上面的介绍中都能找见。
这三个类的功能和主要的用法基本就是这样了。上面所有的链接存储的信息都是操作资源本身自己的,在有些复杂的场景中需要当前资源的链接是用来操作别的资源的。比如:客户customer和订单order之间是一对多关系,获取指定客户的全部订单这个需求是很常见的。
@Getter
@ToString
public class Order extends ResourceSupport {
private String orderId;
private double price;
private int quantity;
}
创建一个方法获取指定用户的所有订单:
@GetMapping("/{customerId}/orders")
public ResponseEntity getOrdersForCustomer(@PathVariable String customerId) {
List<Order> orders = orderService.getAllOrdersForCuntomer(customerId);
for (Order order : orders) {
Link selfLink = linkTo(methodOn(CustomerController.class)
.getOrderByIdForCustomer(customerId, order.getOrderId())).withSelfRel();
order.add(selfLink);
}
Link link = linkTo(methodOn(CustomerController.class).getOrdersForCustomer(customerId))
.withSelfRel();
Resources<Order> result = new Resources<>(orders, link);
return ResponseEntity.ok(result);
}
这个套路也是很简单的,主要是执行下面这条语句先从Controller上找出根路径,再用method追加上子路径,最后包装拼出的URL。上面的方法做的事情也很简单:先给每一个order创建出自己的selfLink并组合,最后创建了一条link用来获取指定用户下的所有orders。Resources是HATEOAS提供的用来简化封装的类,它继承了ResourceSupport,只需要我们将resource和需要的link送给它,其他就不需要我们管了,自己完成了组合。
Link link = linkTo(methodOn(CustomerController.class).getOrdersForCustomer(customerId))
.withSelfRel();
最后看一下展示出来的效果,像_embedded、orderList这些多出来的字段,其实这个结果本身没有多少信息,但是这么多层嵌套和占用这么大的面积给人感觉好复杂的,不说唬住了小白起码也会让人觉得有点烦。可以考虑自己写resource类。
{
"_embedded": {
"orderList": [
{
"orderId": "001A",
"price": 250.0,
"quantity": 25,
"_links": {
"self": {
"href": "http://localhost/customers/10A/orders/001A"
}
}
},
{
"orderId": "002A",
"price": 250.0,
"quantity": 12,
"_links": {
"self": {
"href": "http://localhost/customers/10A/orders/002A"
}
}
}
]
},
"_links": {
"self": {
"href": "http://localhost/customers/10A/orders"
}
}
}
写东西真的好费时间,这种感觉一直都没有变过。把脑海中的零碎片段梳理一下很多时候都要再查资料并且做实验的,不过好处是当这些都弄完的时候我觉着自己的认知更加清楚了些,这也许就是沉淀吧。骑着蜗牛继续向前跑~
参考文档:
https://www.baeldung.com/spring-hateoas-tutorial
27 Nov 2019
对mysql做查询的时候返回值经常是个List<object>,在mapper.xml对应的statement中有时候是resultType有时候却是resultMap。傻傻分不清楚所以总是去找以前的代码看看是怎么写的,等花时间整理的这块的时候才发现用哪个其实很简单,几分钟就能理清楚。博客中提到的查询场景在源码的测试中都有对应。
假设我现在要查询文章,Article类有三个属性:文章的id,文章所属的用户id,文章内容。
public class Article {
private String id;
private String userId;
private String body;
public Article(String userId, String body) {
this.id = UUID.randomUUID().toString();
this.userId = userId;
this.body = body;
}
}
场景一:我要查询一个用户所有文章的Id,很明显查询的结果是个List<String>,别忘了string也是个Object。此时用resultType,先这么记着下面再做解释,对应的statement如下所示:
<select id="findArticles" resultType="java.lang.String">
select id
from articles A
where A.user_id = #{userId}
</select>
场景二:我要查询一个用户的所有文章,不着急根据读写分离的原则我们先定义一个专门用来接收读取的文章的类ArticleData,它的属性跟Article一模一样。
public class ArticleData {
private String id;
private String userId;
private String body;
}
这个查询结果也很明显肯定是个List<ArticleData>,但好多人困惑的是“老虎”、“老鼠”到底用哪个。先用resultMap试试,对应的statement如下所示,给要查的字段取个别名如A.id的别名是articleId,最后在resultMap中将字段名和ArticleData的属性一一映射起来,这样查询就完成了。具体的Mybatis查询语法这里就不解释了。
<sql id="articleData">
select
A.id articleId,
A.user_id articleUserId,
A.body articleBody
</sql>
<select id="findByUserId" resultMap="articleData">
<include refid="articleData"/>
from articles A
where A.user_id = #{userId}
</select>
<resultMap id="articleData" type="com.yang.mybatis.application.data.ArticleData">
<id property="id" column="articleId"/>
<result property="userId" column="articleUserId"/>
<result property="body" column="articleBody"/>
</resultMap>
那能否用resultType呢?答案是可以的。只是有一个要求:被查询的字段的名字必须和接收对象的属性名一样。看个呆萌就就明白什么意思了。statuement得这么写:
<select id="findByUserId" resultType="com.yang.mybatis.application.data.ArticleData">
select
A.id id,
A.user_id userId,
A.body body
from articles A
where A.user_id = #{userId}
</select>
三个待查字段取的别名跟ArticleData中属性的名字一样,否则这种方式就会报错。再回头看下场景一的查询,是因为String能匹配任意字符串。