mysql redo log和binlog
21 Feb 2020学习还是需要做笔记的,如果读书是输入那么笔记就是对应的输出了。脑子里觉得”理解了“的内容当把它用文字以书面形式表达出来的时候是对刚才的理解进一步地整理、确认(可能这种理解存在在着错误)。写博客也是做笔记的一种形式,但它却更费时间,之前的博客废话有点多了,以后注意,毕竟效率也是很重要的。进入正题…………
mysql的逻辑架构(如下图所示):
- 连接器管理连接、校验权限、维持和管理权限,当我们在terminal中输入
mysql -uroot -p12345时就通过连接器建立客户端与mysql服务器的连接。本地使用的时客户端和服务器都在同台电脑上,上述命令可以直接建立连接。 - 查询缓存按照
key-value的格式存放之前的查找记录。key是分析器放入的,对应的value是执行器放入的。当执行SQL语句的时候会先查询缓存有无命中,如果有则直接返回查询结果。当一张表有update操作时,这张表上的查询缓存全部失效。 - 分析器会对要执行的SQL语句进行词法分析和语法分析,判断语法是否正确,要查询的结果、查询的条件等信息。
- 优化器会在多个执行方案找出最优方案。比如:通过优化器模MySQL已经知道当前语句要查找某个记录,优化器会决定是走全表查找还是按索引查找。
- 执行器根据优化方案执行具体的查找操作。先校验当前用户对表有没有查找权限,如果有则执行器通过引擎提供的接口打开表,按照全行扫描或者索引查找记录,最后将满足条件的记录组成结果集返回给客户端。
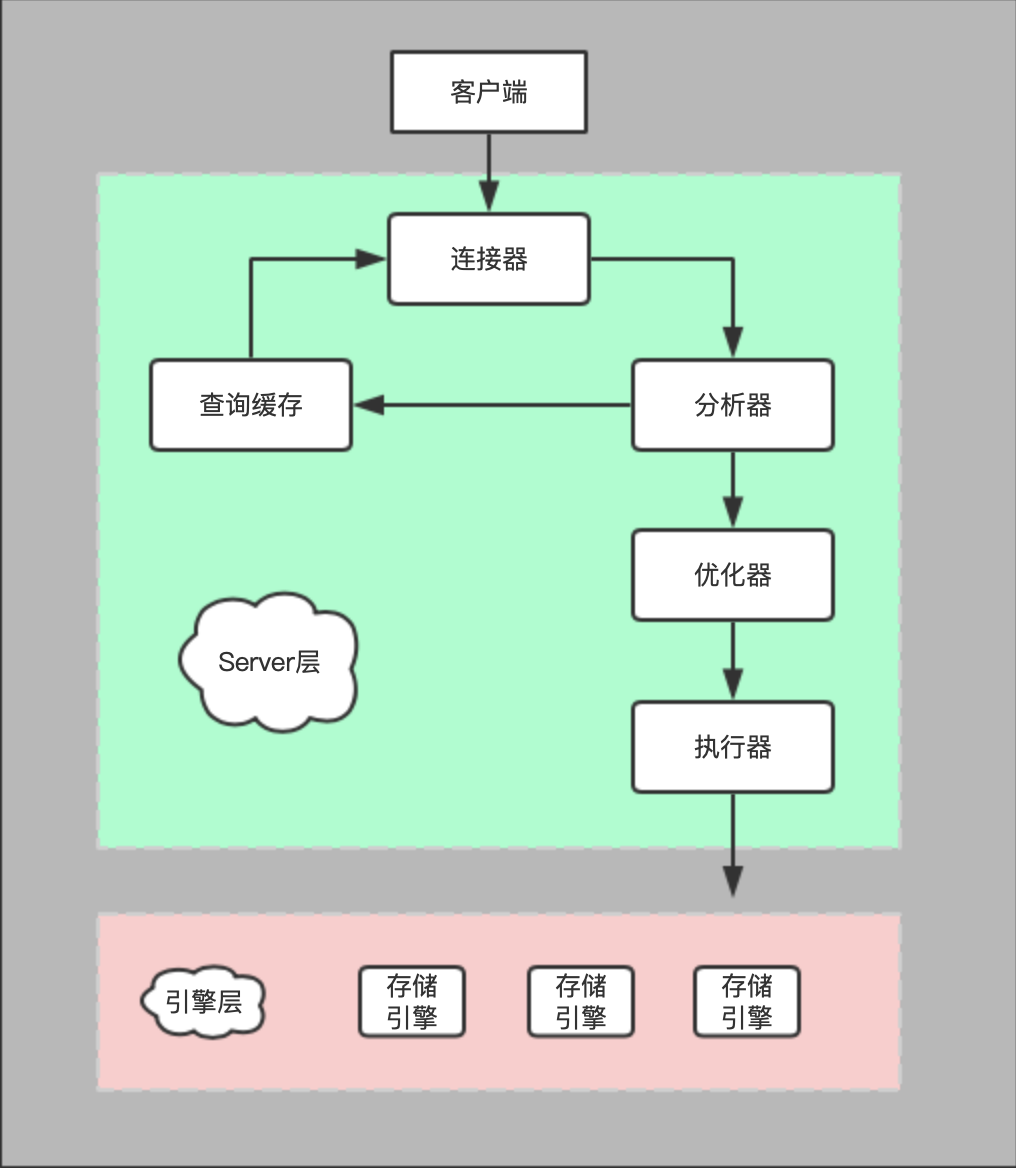 mysql的逻辑架构图
mysql的逻辑架构图一条SQL语句的执行过程。
创建表:
create table T(ID int primary key, c int);
更新一行记录:
update T set c=c+1 where ID=2;
update语句执行流程如下:
- 执行器要调用引擎接口拿到ID=2这行记录。(服务层)
- 引擎层直接在ID索引树上查找目标数据,如果目标数据所在的数据页在内容中,则直接返回给执行器,否则,先要从磁盘中读数据页到内存中,再将目标数据返回给执行器。(引擎层)
- 执行器拿到行数据后,给对应字段的原值+1得到一行新的数据,再调用引擎接口将新数据交给引擎层去写。(服务层)
- 事务执行commit语句后,引擎层将拿到的新数据更新到内存中,同事将这个更新写到
redo log里面,此时redo log处于prepare状态。然后告诉执行器新数据写完了,可以提交事务了。(引擎层) - 执行器收到引擎层的“可提交”通知后将刚才的更新操作写到到
binlog里面。(服务层) - redo log写入磁盘。(引擎层)
- binlog写入磁盘。(服务层)
- 执行器调用引擎提交事务接口,引擎把刚刚写入redo log的状态标改成提交(commit)状态,更新结束,(WAL机制)。(引擎层)。
第4步后将redo log的提交分为了prepare和commit两个阶段,这就是两阶段提交
更新的执行过程中在服务层和引擎层来回切换赶脚好乱,我第一次看感觉就是头大,但梳理下还是很清楚的,搞清楚几个问题就可以初步理解了:
1 mysql服务端由那几部分构成?
大体来说,MySQL可以分为服务层和引擎层两部分。
服务层包括连接器、查询缓存、分析器、优化器、执行器等大多数服务功能,数据的计算也在这层执行。引擎层**只负责数据的读取和存储。
服务层只有一种,但引擎层支持多重存储引擎,比如:MYISAM、InnoDB、Memory都是具体的存储引擎,服务层也都支持。InnoDB是最长用的存储引擎。
2 redo log和binlog是什么?
简单说,这两个都是日志,
redo log是InnoDB引擎特有的日志,binlog是服务层的日志(所有引擎都能使用该日志)。
redo log是物理日志,记录了每个数据页上做了什么修改,比如将第 0 号表空间的 100 号页面的偏移量为 1000 处的值更新为 2,binlog是逻辑日志,有两种模式:statement格式下记录时sql语句,rows格式会为更新的行记录两条内容,一条是更新前的内容,另一条是更新后的。(所有的引擎都能看懂)。
redo log是循环写的,总共大小默认4G,当日志写满是会把最开始的记录刷到磁盘中,腾出空间给新记录。binlog是追加写的,类似于文件一张一张写满又新建一张继续追加写,永远不会覆盖。
4 为什么要记录两份日志?
mysql需要做两样工作:备份和crash-safe(突然崩溃后不能丢失数据)。
当只有redo log:因为它是循环写的,写到末尾是要擦除开头重新写,这样就没法保存历史日志,所以能用来备份。
当只有binlog不能保证MySQL有crash save能力。(至于原因,看了好些资料觉得都没有完全解释,或许是我吗没有理解)
5 MySq如何保证crash save?
Crash save是指mysql服务器宕机重启后,能够保证:所有已提交的事务的数据仍旧存在,所有未提交的事务的数据回滚。MySQL的两阶段提交恰好保证了mysql具有crash save能力,来看下具体的细节:
当写redo log成功,在binlog之前宕机,MySQL重启时发现有redo log中的事物却没在binlog中找到对应的完整事务,则回滚。
当写redo log成功,写binlog成功,但在redo log状态变为commit时宕机,MySQL重启时发现redo log中完整的事物能在redo log中找到对应的而且也完整,则重新将这个事务提交。
6 MySQL怎么知道binlog中的事物是否完整,怎么将redo log和binlog中的事务对应起来?
binlog中的事务都是有完整格式的:
statement格式:事务后面会有个commit。 row格式:最后会有个XID event。
事务都有个共同的字段XID,redo log和binlog通过这个字段将相同的事务关联起来。
7 什么是WAL(write-ahead log)机制, 好处是什么?
WAL机制是当执行更新语句时,引擎将更新语句记录在redo log上提后向客户端返回“更新成功”,等到MySQL觉得合适的时间在将redo log上的刷到磁盘上。
这样做的好处是:直接把数据写到磁盘上,频繁的随机写会耗费大量的时间。写在redo log上就可以把随机写变成顺序写,效率提高好多。